What a Random Forest and How is it Different?
The random forest method of model creation contains certain elements of both the bagging, and standard tree methodologies. The random forest sampling step is similar to that of the bagging model. Also, in a similar manner, the random forest model is comprised of numerous individual trees, with the output figure being the majority consensus reached as data is passed through each individual tree model. The only real differentiating factor which is present within the random forest model, is the initial nodal split designation, which occurs proceeding the model’s root pathway.
For example, if the following data frame was structured and prepared to serve as a random forest model’s foundation, the first step which would occur during the initial algorithmic process, would be random sampling.

Like the bagging model’s sampling process, the performance of this step might also resemble:
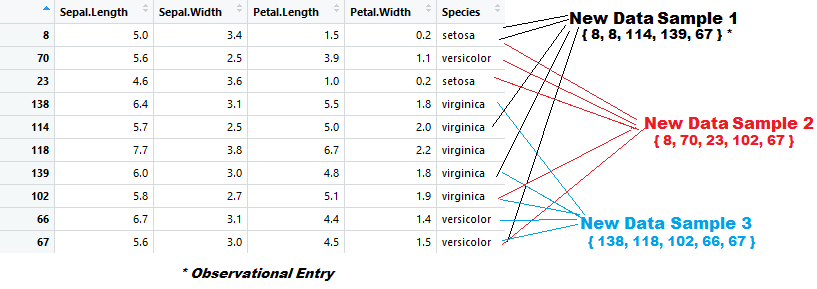
As it pertains to the random forest model, after the creation of each individual set has been established, a pre-selected number of independent variable categories are designated at random from each set, this selection will be assessed by the algorithm, with the most optimal pathway being ultimately selected from amongst the selection of pre-determined variables.
For example, we’ll assume that the number of pre-designate variables which will be selected prior to the creation of each individual tree is 3. If this were the case, each tree within the model will have its initial nodal designation decided upon by which one of the three variables is optimal as it pertains to performing the initial filtering process. The other two variables which are not selected, are then considered for additional nodal splits, along with all of the other variables which the model finds particularly worthy.
With this in mind, a set of variables which would consist of three randomly selected independent variables, might resemble the following as it relates to the initial nodal split:

One variable would be selected from the set, with the other two variables then being returned to the larger set of all other variables from the initial data frame. From this larger set, all additional nodes would be established based on the optimal placement values determined by the underlying algorithm.
The Decision-Making Process
In a manner which exactly resembles the bagging-boostrap aggregation method described within the prior article, the predictive output figure consists of the majority consensus reached as data is passed through each individual tree model.

A Real Application Demonstration (Classification)
Again, we will utilize the "iris" data set which comes embedded within the R data platform.
# Create a training data set from the data frame: "iris" #
# Set randomization seed #
set.seed(454)
# Create a series of random values from a uniform distribution. The number of values being generated will be equal to the number of row observations specified within the data frame. #
rannum <- runif(nrow(iris))
# Order the data frame rows by the values in which the random set is ordered #
raniris <- iris[order(rannum), ]
# With the package "randomForest" downloaded and enabled #
# Create the model #
mod <- randomForest(Species ~., data= raniris[1:100,], type = "class")
# View the model summary #
mod
Console Output:
Call:
randomForest(formula = Species ~ ., data = raniris[1:100, ], type = "class")
Type of random forest: classification
Number of trees: 500
No. of variables tried at each split: 2
OOB estimate of error rate: 4%
Confusion matrix:
setosa versicolor virginica class.error
setosa 31 0 0 0.00000000
versicolor 0 34 1 0.02857143
virginica 0 3 31 0.08823529
Deciphering the Output
Call: - The formula which initially generated the console output.
Type of random forest: Classification – The model type applied to the data frame passed through the “randomForest()” function.
Number of trees: 500 – The number of individual trees from which the data model is comprised of.
No. of variable tried at each split: 2 – The number of randomly selected variables considered as candidates for the initial nodal split criteria.
OOB estimate of error rate: 4% - The amount of erroneous predictions which were discovered within the model as a result of passing OOB (out of bag) data through the completed model.
Class.error – The percentage which appears within the rightmost column represents the total number of observations within the row divided by the number of incorrectly categorized observations within the row.
OOB and the Confusion Matrix
OOB is an abbreviation for “Out of Bag”. As it pertains to the random forest model, as each individual tree is being established within the model, additional observations from the original data set will, as a consequence of the method, not be selected for inclusion as it pertains to the creation the subsets. To generate both the OOB estimate of the error rate, and the confusion matrix within the object summary, the withheld data is passed through each individual tree once it is created. Through an internal tallying and consensus methodology, the confusion matrix presents an estimate of all observational predictions which existed within the initial data set, however, not all of the observational values which were predicted through this method were evenly assessed throughout the entire series of tree models. The consensus is that this test of prediction specificity is superior to testing the complete model with the entire set of initial variables. However, due to the level of complexity which is innate within the methodology, which, as an aspect of such, makes explaining findings to others extremely difficult, I will often also run the standard prediction function as well.
# View model classification results with training data #
prediction <- predict(mod, raniris[1:100,], type="class")
table(raniris[1:100,]$Species, predicted = prediction )
# View model classification results with test data #
prediction <- predict(mod, raniris[101:150,], type="class")
table(raniris[101:150,]$Species, predicted = prediction )
Console Output (1):
predicted
setosa versicolor virginica
setosa 31 0 0
versicolor 0 35 0
virginica 0 0 34
Console Output (2):
predicted
setosa versicolor virginica
setosa 19 0 0
versicolor 0 13 2
virginica 0 2 14
As you probably already noticed, the “Console Output (1)” values differ from those produced within the object’s Confusion Matrix. This is a result of the phenomenon which was just previously discussed.
To further illustrate this concept, if I were to change the number of trees to be created to: 2, thus, overriding the package default, the Confusion Matrix will lack enough observations to reflect the total number of observations within the initial set. The result would be the following:
# With the package "randomForest" downloaded and enabled #
# Create the model #
mod <- randomForest(Species ~., data= raniris[1:100,], ntree= 2, type = "class")
# View the model summary #
mod
Call:
randomForest(formula = Species ~ ., data = raniris[1:100, ], ntree = 2, type = "class")
Type of random forest: classification
Number of trees: 2
No. of variables tried at each split: 2
OOB estimate of error rate: 3.57%
Confusion matrix:
setosa versicolor virginica class.error
setosa 15 0 0 0.00000000
versicolor 0 19 0 0.00000000
virginica 0 2 20 0.09090909
Peculiar Aspects of randomForest
There are few particular aspects of the randomForest package which differ from the previously discussed packages. One of which is how the randomForest() assesses variables within a data frame. Specifically, as it relates to such, the package function requires that variables which will be analyzed must have their types specifically assigned.
To address this, we must first view the data type in which each variable is assigned.
This can be accomplished with the following code:
str(raniris)
Which produces the output:
'data.frame': 150 obs. of 5 variables:
$ Sepal.Length: num 5 5.6 4.6 6.4 5.7 7.7 6 5.8 6.7 5.6 ...
$ Sepal.Width : num 3.4 2.5 3.6 3.1 2.5 3.8 3 2.7 3.1 3 ...
$ Petal.Length: num 1.5 3.9 1 5.5 5 6.7 4.8 5.1 4.4 4.5 ...
$ Petal.Width : num 0.2 1.1 0.2 1.8 2 2.2 1.8 1.9 1.4 1.5 ...
$ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 2 1 3 3 3 3 3 2 2 ...
While this data frame does not require additional modification, if there was a need to change or assign variable types, this can be achieved through the following lines of code:
# Change variable type to continuous #
dataframe$contvar <- as.integer(dataframe$contvar)
# Change variable type to categorical #
dataframe$catvar <- as.factor(dataframe$catvar)
Another unique differentiation which applies to the randomForest() function is the way in which it handles missing observational variable entries. You may recall from when we were previously building tree models within the “rpart” package, that the model methodology included within such contained an internal algorithm which assessed missing variable observational values, and assigned those values “surrogate values” based on other similar variable observations.
Unfortunately, the randomForest() function requires that the user take a on more manual approach as it pertains to working around, and otherwise including these observational values within the eventual model.
First, be sure that all variables within the model are appropriately assigned to the correct corresponding data types.
Next, you will need to impute the data. To achieve this, you will need to utilize the following code for each variable column which is absent data.
# Impute missing variable values #
rfImpute(variablename ~., data=dataframename, iter = 500)
This function instructs the randomForest package library to create new variable entries for whatever the specified variable may be by considering similar entries contained with other variable columns. “iter = “ specifies the number of iterations to utilize when accomplishing this task, as for whatever reason, this method of variable generation requires the creation of numerous tree models. A maximum of 6 iterations is enough to accomplish this task, however, I err on the side of extreme caution. If your data frame is colossal, 6 iterations should suffice.
Though it’s un-necessary, let’s apply this function to each variable within our “iris” data frame:
raniris[1:100,]$Sepal.Length <- rfImpute(Sepal.Length ~., data=raniris[1:100,], iter = 500)
raniris[1:100,]$Sepal.Width <- rfImpute(Sepal.Width ~., data=raniris[1:100,], iter = 500)
raniris[1:100,]$Petal.Length <- rfImpute(Petal.Length ~., data=raniris[1:100,], iter = 500)
raniris[1:100,]$Petal.Width <- rfImpute(Petal.Width ~., data=raniris[1:100,], iter = 500)
raniris[1:100,]$Species <- rfImpute(Species ~., data=raniris[1:100,], iter = 500)
You will receive the error message:
Error in rfImpute.default(m, y, ...) : No NAs found in m
Which correctly indicates that there were no NA values to be found in the initial set.
Variables to Consider for Initial Nodal Split
The randomForest package has embedded within its namesake function, a default assignment as it pertains to the number of variables which are consider for each initial nodal split. This value can be modified by the user for optimal utilization of the model’s capabilities. The functional option to specify this modification is “mtry”.
How would a researcher decide what the optimal value of this option ought to be? Thankfully, a Youtube user named: StatQuest with Josh Starmer, has created the following code to assist us with this decision.
# Optimal mtry assessment #
# vector(length = ) must equal the number of independent variables within the function #
# for(i in 1: ) must have a value which equals the number of independent variables within the function #
oob.values <- vector(length = 4)
for(i in 1:4) {
temp.model <- randomForest(Species ~., data=raniris[1:100,], mtry=i, ntree=1000)
oob.values[i] <- temp.model$err.rate[nrow(temp.model$err.rate), 1]
}
# View the object #
oob.values
Console Output
[1] 0.04 0.04 0.04 0.04
The values produced are the OOB error rates which are associated with each number of variable inclusions.
Therefore, the leftmost value would be the OOB error rate with one variable included within the model. The rightmost value would be the OOB error rate with four variables included with the model.
In the case of our model, as there is no change in OOB error as it pertains to the number of variables utilized for initial nodal split consideration, the option “mtry” can remain unaltered. However, if for whatever reason, we wished to consider a set of 3 random variables for each initial split within our model, we would utilize the following code:
mod <- randomForest(Species ~., data= raniris[1:100,], mtry= 3, type = "class")
Graphing Output
There are numerous ways to graphically represent the inner aspects of a random forest model as its aspects work in tandem to generate a predictive analysis. In this section, we will review two of the simplest methods for generating illustrative output.
The first method creates a general error plot of the model. This can be achieved through the utilization of the following code:
# Plot model #
plot(mod)
# include legend #
layout(matrix(c(1,2),nrow=1),
width=c(4,1))
par(mar=c(5,4,4,0)) #No margin on the right side
plot(mod, log="y")
par(mar=c(5,0,4,2)) #No margin on the left side
plot(c(0,1),type="n", axes=F, xlab="", ylab="")
# “col=” and “fill=” must both be set to one plus the total number of independent variables within the model #
legend("topleft", colnames(mod$err.rate),col=1:4,cex=0.8,fill=1:4)
# Source of Inspiration: https://stackoverflow.com/questions/20328452/legend-for-random-forest-plot-in-r #
This produces the following output:

varImpPlot(mod)

A Real Application Demonstration (ANOVA)
# Create a training data set from the data frame: "iris" #
# Set randomization seed #
set.seed(454)
# Create a series of random values from a uniform distribution. The number of values being generated will be equal to the number of row observations specified within the data frame. #
rannum <- runif(nrow(iris))
# Order the dataframe rows by the values in which the random set is ordered #
raniris <- iris[order(rannum), ]
# With the package "ipred" downloaded and enabled #
# Create the model #
anmod <- randomForest(Sepal.Length ~ Sepal.Width + Petal.Length + Petal.Width, data = raniris[1:100,], method="anova")
Like the previously discussed methodologies, you also have the option of utilizing Root Mean Standard Error, or Mean Absolute Error, to analyze the model’s predictive capacity.
# Compute the Root Mean Standard Error (RMSE) of model training data #
prediction <- predict(anmod, raniris[1:100,], type="class")
# With the package "metrics" downloaded and enabled #
rmse(raniris[1:100,]$Sepal.Length, prediction )
# Compute the Root Mean Standard Error (RMSE) of model testing data #
prediction <- predict(anmod, raniris[101:150,], type="class")
# With the package "metrics" downloaded and enabled #
rmse(raniris[101:150,]$Sepal.Length, prediction )
# Mean Absolute Error #
# Create MAE function #
MAE <- function(actual, predicted) {mean(abs(actual - predicted))}
# Function Source: https://www.youtube.com/watch?v=XLNsl1Da5MA #
# Regenerate Predictive Model #
anprediction <- predict(anmodel , raniris[1:100,])
# Utilize MAE function on model training data #
MAE(raniris[1:100,]$Sepal.Length, anprediction)
# Mean Absolute Error #
anprediction <- predict(anmodel , raniris[101:150,])
# Utilize MAE function on model testing data #
MAE(raniris[101:150,]$Sepal.Length, anprediction)
Console Output (RMSE)
[1] 0.2044091
[1] 0.3709858
Console Output (MAE)
[1] 0.2215909
[1] 0.2632491
Just like the classification variation of the random forest model, graphical outputs can also be created to illustrate the internal aspects of the ANOVA version of the model.
# Plot model #
plot(anmod)

varImpPlot(anmod)

That's all for this entry, Data Heads.
We'll continue on the topic of machine learning next week.
Until then, stay studious!
-RD
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.